Most people don’t realise this, but many YouTube videos have built-in transcripts. You can open them up, copy & paste, and suddenly you have the whole video in text form.
Sounds handy, right? The problem is, doing it manually is a pain in the peppu – well, you get the idea. Many a times I have wanted to keep notes from a good talk or lecture, only to give up halfway through endless scrolling, selecting and pasting.
That annoyance was the spark for my latest little side project: a script-pulling tool that automatically grabs transcripts from YouTube videos, cleans the transcript, and saves them into a folder and adds the item to a list. No more fiddly copying. Just clean text, organised, ready to be fed to an LLM, searched, analysed and reflected on.
If this sounds familiar, it’s because I’ve been exploring similar workflows before. In an earlier post I wrote about moving from PDFs to conversations with GPT4All’s LocalDocs. That experiment was about making written sources more conversational. This new one is about making video content more usable. Different medium, same idea: now changing modality of the content into something I can actively learn from.
And just to complicate the order of things: right after pulling YouTube transcripts, I actually went back to LocalDocs testing in GPT4All with my new clean.txt files (I’ll explain this later). That worked wonderfully. If you think about it, these posts are appearing in the “wrong” order. But that’s how I usually work, rarely linear, not always tidy, but always moving forward.
In this project I use Christopher Hitchens as the subject.
What you can learn from transcripts
Once you have a transcript, the way you engage with the material changes. Reading makes it possible to see the structure of an argument, to skim for key points, and to pull useful passages into other tools for analysis. Having multiple texts from or about the same person helps to find patterns, recurring themes and strategies.
I found myself noticing connections between videos I wouldn’t have caught by just listening. I also started spotting recurring themes, now the beauty here is an LLM can verify and confirm this in almost an instant. At a higher level, this reflects well-established approaches such as Conversation Analysis and Corpus Linguistics. These frameworks, developed internationally but strongly rooted at the University of Helsinki through scholars like Auli Hakulinen, Marja-Leena Sorjonen and others treat collections of transcripts as systematic data. The point is not one isolated text, but the accumulation of many, which makes it possible to uncover recurring practices, themes, and strategies in interaction. In this sense, my experiment aligns closely with discourse analysis traditions at the University of Helsinki, where the focus is on how repeated instances of language use reveal broader patterns of meaning and strategy.
Why I write things down
As a lifelong learner, I don’t see YouTube only as entertainment but as a medium for education. Watching debates, lectures, and interviews is one thing — but engaging with their transcripts takes it further, turning fleeting speech into material that can be analysed, revisited, and connected to other ideas. Educational psychologist Richard E. Mayer argues in Multimedia Learning that meaningful learning occurs when learners select relevant information, organise it into coherent mental representations, and integrate it with their existing knowledge. Mayer, R. E. (2009). Multimedia learning (2nd ed.). Cambridge University Press. (For an accessible version, see the JSU-hosted PDF).
In this sense, my transcript work is not just about collecting texts; it is a way of transforming media encounters into lasting learning experiences.
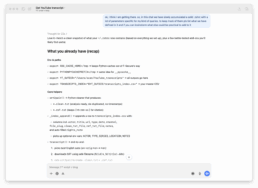
How we built it (the high-level view)
Since readers often ask for the how as much as the why, here’s the outline of what we actually did.
The workflow was simple:
- Fetch the transcript → Use YouTube’s transcript data instead of manually copying from the built-in viewer.
- Generate multiple versions → We produced at least two, sometimes three files for each video:
- a
.txtwith timestamps, so I could later revisit the video or reference specific points, - a
.txtclean version, stripped of all timing markers and quirks, - and occasionally an
.srtsubtitle file (though I’m not entirely sure anymore why we needed that).
- a
- Organise into a list → Add metadata such as video titles, links, and dates of when each transcript was pulled into a .csv file.
After this build phase came the “academic” part: with GPT4All’s LocalDocs it was as simple as creating a new Collection by pointing to the folder of cleaned text files. From there, I could open a chat and immediately start using that material for analysis, comparison, and even conversation. For an in-depth how to see my previous blog post.
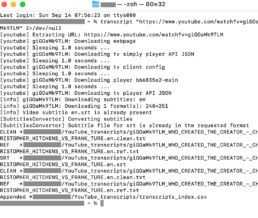
Digging deeper: under the hood
For those who want more detail, here’s what happened under the hood and full disclosure: I didn’t code this myself. I had the idea and the vision, while OpenAI’s GPT-5 provided the instructions and snippets that made it work.
As a non-coder I often stumbled on basic things: where exactly to run a command in the Terminal (on macOS or Command Prompt on pc), how to deal with strange error messages, or how to keep files from ending up in the wrong folders. These hurdles slowed me down, but they were also part of the learning curve.
- Terminal-driven workflow → Everything was run from the command line. A single command pulled the transcript, cleaned it, and generated the file set.
- Automated file outputs → The script created the three versions in one go: timestamped
.txt, clean.txt, and sometimes.srt. - CSV as a ledger → Each new transcript was automatically appended as a row in a CSV file, with metadata like title, URL, and date added. This kept the library organised and avoided duplicates.
- Compact but not tiny → While it wasn’t hundreds of lines, the script had to juggle fetching, cleaning, file handling, and CSV updates.
Well, then of course you ask yourself, why would I run the script for every single video? Can I pull transcripts from multiple videos at once or rather chain them? Yes, you can! So, I asked the bot to create a script that would fetch the Top50 Hitchens videos on YouTube and it did. Convenient! Then it was just instructing the bot to update the script to fetch the URL from each line and pull the transcripts. I didn’t ask it to do all 50, but 10 for testing purposes.
The philosophy stayed the same: keep it lightweight, focus on doing one job well. But in practice, the script had to cover fetching, cleaning, file handling, and CSV updates, so “small” is relative. It was compact, yes, but not a single throwaway snippet. And as icing on the cake, I learned how to use GitHub, properly enough: setting up a repository, connecting it, and automating the saving of my shell configuration files (like .zshrc) into it. Through a few Terminal commands I linked my machine to GitHub so that changes to those config files are version-controlled and pushed automatically. (To be clear: this GitHub automation is for my config files (the ones that orchestrate the pulling of transcripts etc.), the transcripts themselves live locally for LocalDocs.) For a non-coder, this was a revelation, suddenly the whole process felt not just functional but also properly backed up and maintainable.
From code to reflection
So yes, I “wrote” some scripts. I tinkered with list management. I fixed duplicates. All very geeky. But what I really built was a workflow that nudges me from watching to learning AND once again proved how very useful chatbots can be. I am still amazed about the possibilities we nowadays have. It feels new opportunites are everywhere; if I have an tech-based idea or a problem and if I can formulate it, I very often am able to find a solution or workaround with the help of a chatbot.
You may ask why did I use a commercial chatbot (ChatGPT) to help me take this idea from concept through to execution and not an LLM locally via GPT4ALL? My answer probably could be a post itself, but the short answer is: local LLMs (the ones I can run on my machine) are in my, admittedly short experience, not as capable as GPT5. I need to explain too much, GPT-4o and GPT-5 “know” me and are very conversational – less like chatbotty =)
What’s up next?
Video made with Midjourney.
[…] and handled the surrounding implementation steps myself, see Threat assessment monitoring tool and Pulling YouTube scripts . Here, the intention was to see how far the system could carry the process from idea to working […]