Large language models are usually encountered as subscription services in the cloud. You type a question into ChatGPT or Gemini, the answer comes back, and somewhere out of sight a data centre has done the work. For many tasks that is perfectly fine, but there are good reasons to consider running language models locally.
Why local matters
Local LLMs, tools such as Ollama, GPT4All, LM Studio and others, run directly on your own computer. Instead of sending data to a remote server, the model sits on your hard drive and responds without leaving the machine.
When we talk about how a language model works, two stages matter. First is training, where the model is built on huge datasets in specialised data centres, something individual users do not typically undertake. Second is inference, which simply means the model generating answers from a prompt. It is this inference stage that we run locally on our own machines, and it is where the differences between cloud and local approaches become visible in terms of privacy, cost and energy use.
This matters in academia for several reasons:
-
Privacy: Your files remain on your own computer, a useful feature if you are dealing with unpublished drafts, student work, or sensitive research data.
-
Offline use: The model continues to function without an internet connection.
-
No ongoing cost: Once the model is installed, usage is free, no API fees or subscriptions.
-
Transparency and reproducibility: You control the model and its version, no surprises from cloud updates.
-
Energy profile: Local use shifts the environmental discussion. Instead of depending on the large-scale infrastructure of cloud providers, with their considerable energy and cooling needs, the work happens on a single machine. The total impact may be smaller, but it is also more visible to the user in the form of fan noise, battery drain, and warmth on the desk.
The trade-off is that local models are generally smaller and less powerful than their cloud cousins. Answers can be simpler, sometimes less nuanced, and running them efficiently requires a reasonably modern computer. Still, for many academic use cases the balance is an attractive one.
Enter GPT4All and LocalDocs
Among the local options, GPT4All stands out for its straightforward interface and its LocalDocs feature. This is GPT4All’s way of implementing what is known as retrieval augmented generation (RAG).
Here is the distinction: attaching a document in a chat usually means feeding the entire file into the prompt, which then has to be sent back and forth each time you ask a question in that session. This is inefficient and can quickly run into token limits. RAG, by contrast, retrieves only the most relevant passages from your indexed collection and passes those to the model. The result is both more efficient and more accurate.
Inference: local and cloud contrasted
Indexing all your PDFs takes some effort, chunking, embedding, indexing, but that is a one-time task. The real work, inference (i.e. answering questions), is where usage and energy differ:
-
- Cloud models (e.g. GPT-4): A recent benchmarking study of LLM inference energy use (Jegham et al., 2025) reports that a short GPT-4 query consumes about 0.43 Wh, while long prompts can rise above 30 Wh (arXiv preprint).
- Local small models: In practice these tend to use less energy per query than large cloud-hosted models, though precise measurements are hard to find. I have not come across solid published studies that give exact figures, but the general expectation is that local use trades depth and scale for efficiency and privacy.
- Academic findings also show that inference now comprises the majority of a model’s lifecycle carbon emissions, with energy varying strongly based on model size, prompt tokens, batching, and hardware (see for example Liu et al., 2025, arXiv preprint).
Beyond electricity, there is also the matter of cooling: cloud data centres consume vast amounts of water to keep servers at operating temperature, an environmental cost absent when running a model on your laptop.
In short: cloud models offer unmatched depth and speed, but at higher energy and infrastructure cost. Local alternatives are leaner, private, and often sufficient for most reading or summarising tasks.
A case study: twenty-four PDFs, 850,000 words
I have been testing Ollama for a while, but have not been convinced by the capabilities of the open source LLMs installed locally. As stated above they are not as capable reasoning wise as cloud based ones. It’s more like fiddling aroud with GPT-3.5, if you happen to remember those times.
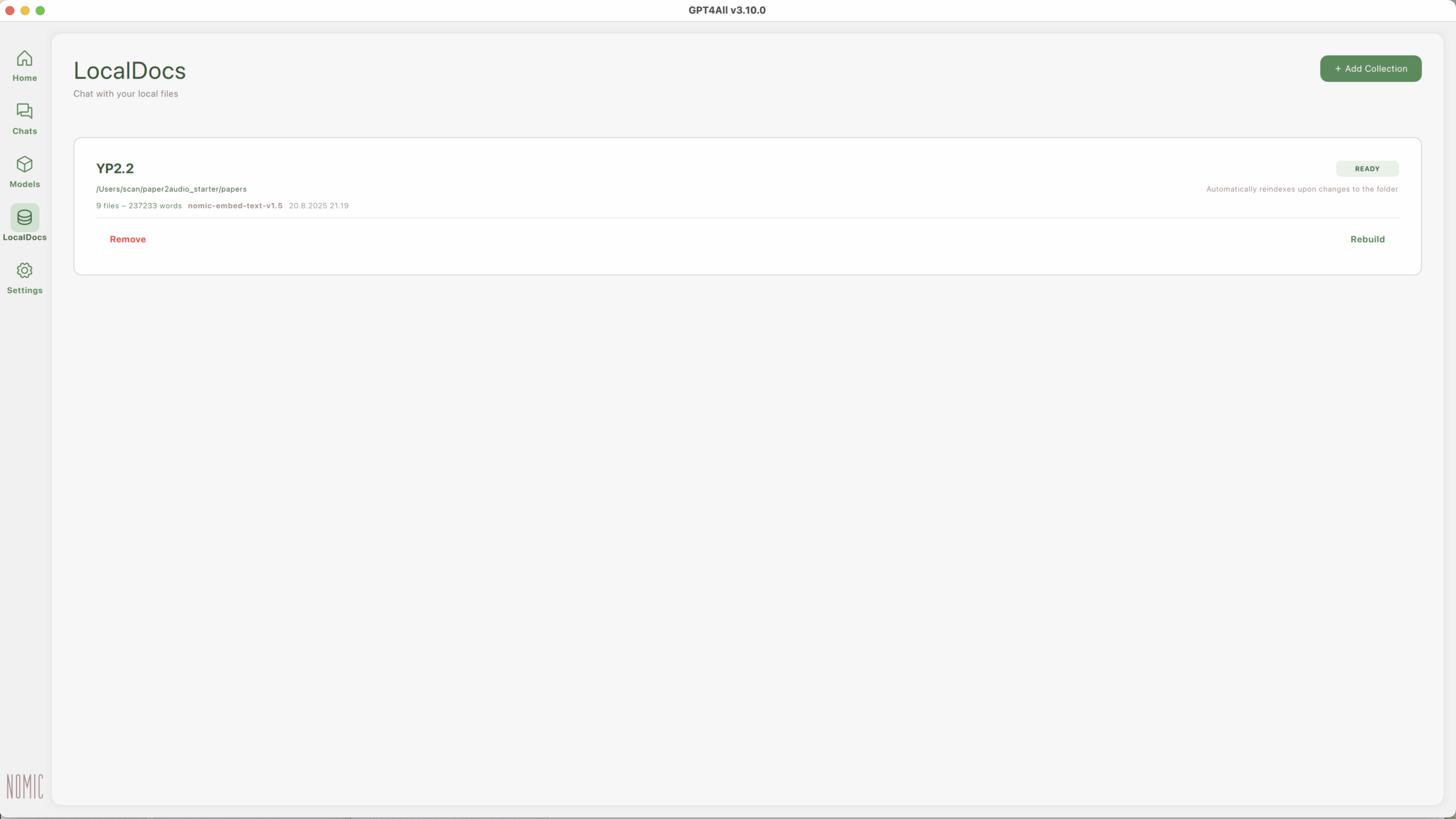
Now, Lydia Cao (LinkedIn) posted about GPT4All, a tool I had not come across yet. I was intrigued byt its LocalDocs functionality, in other words a propoer RAG. I wanted to test GPT4All and see how this feature really fares. To do this, I created a collection of twenty-four PDFs and txt files about cooking containing roughly 850,000 words. I found excellent open access sources such as Project Gutenberg, FAO, Recipe Graveyard etc. On my Mac’s hard drive I created a folder where I put all the 24 files in. Creating a LocalDocs Collection is a very straight forward thing, you click + Add Collection, name it appropriately and choose the folder you have prepared. Now starts the indexing; which is probably the most energy intensive phase. This process can take a noticeable amount of time, but the user is kept in the loop with an Embedding in progress counter.
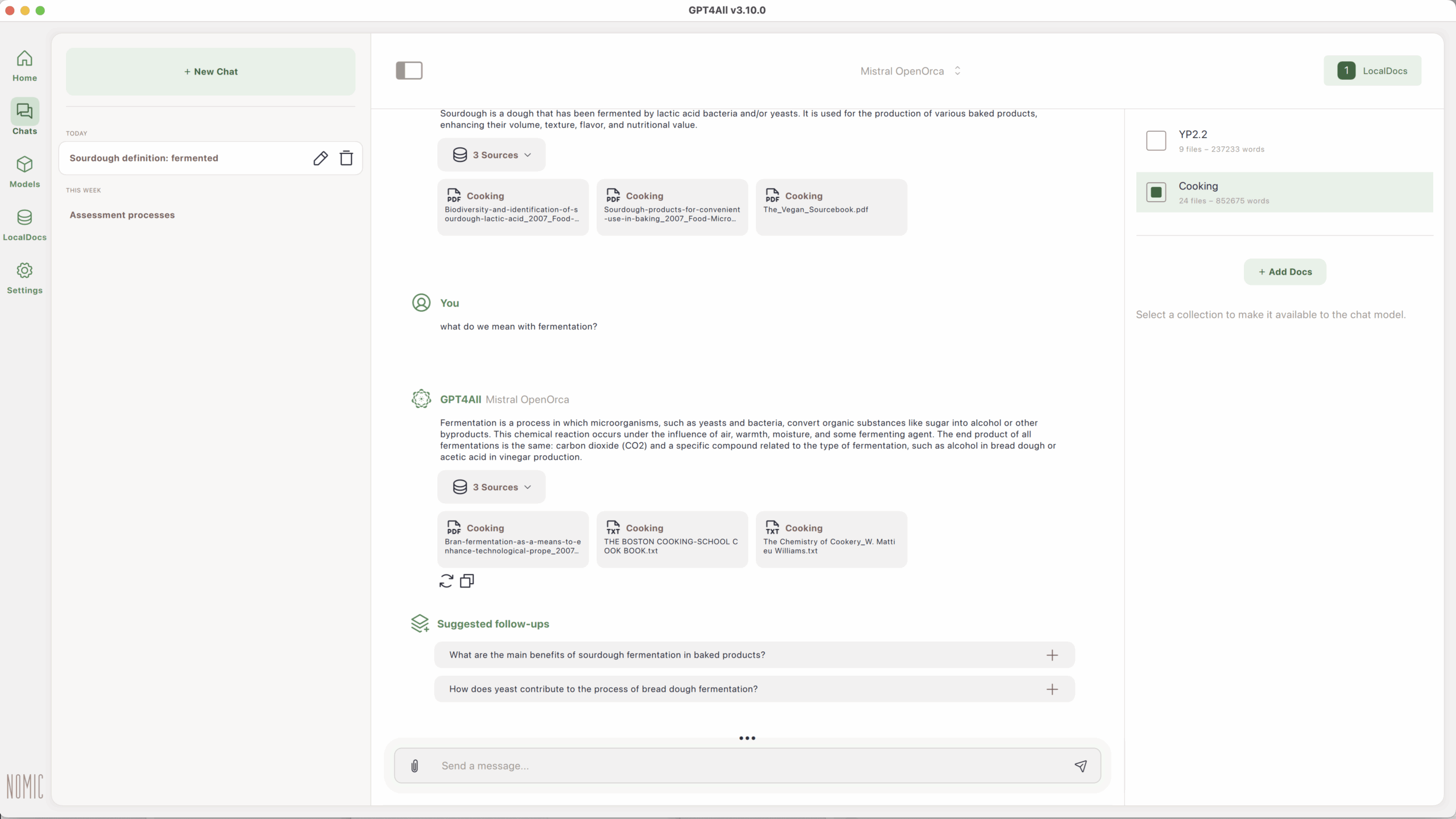
Once done, with the correct LocalDocs collection selected I can ask basic questions in the chat eg.:
- What is fermentation?
- What are some health risks around eating red meat?
- What is the most cited ingredient across these sources?
The responses are drawn directly from my own materials, not from the internet at large; in fact as far as I understand it the LLM cannot browse the internet and look for live information.
But when I ask a question not related to the content of the collection, say “What is a jaybird?” the LLM responds: “A jaybird is a small, colorful bird found in the Corvidae family. It is not mentioned in any of the provided excerpts.” Hallucination and straight up lying is minimised, although I still would double check before publishing anything academic…
Note, this was a quick test, not a deep-dive. I am sure as I am using this more pros and cons will emerge.
Benefits and limits
For higher education, the benefits are clear:
-
Teachers can make course readings searchable.
-
Researchers can mine their own article archives.
-
Administrators can query policy documents without wading through endless PDFs.
There are limits too: smaller models cannot always match the reasoning depth of GPT-4, indexing large collections takes time, and running locally requires a capable machine. Cloud models remain useful for complex or highly creative work.
One caveat is worth mentioning. Just because documents can be indexed does not mean that all documents should be. Copyrighted materials, institutional policies, or student work still need to be handled with the same care as they would in any other context. Local deployment keeps files on your machine, but the responsibility for using them appropriately remains with us.
Conclusion
Local LLMs will not replace cloud services outright, but they offer something different: privacy, control, and the ability to put our own documents back into play. For academics, that can mean less time scrolling through PDFs and more time thinking about what the documents actually say. What would be your use case?
[…] this sounds familiar, it’s because I’ve been exploring similar workflows before. In an earlier post I wrote about moving from PDFs to conversations with GPT4All’s LocalDocs. That experiment was […]